Extract structured data from any document
Your data is never used for training
Features with dedicated guides
Each feature below has its own detailed page: how it works, a concrete example, and the API integration.
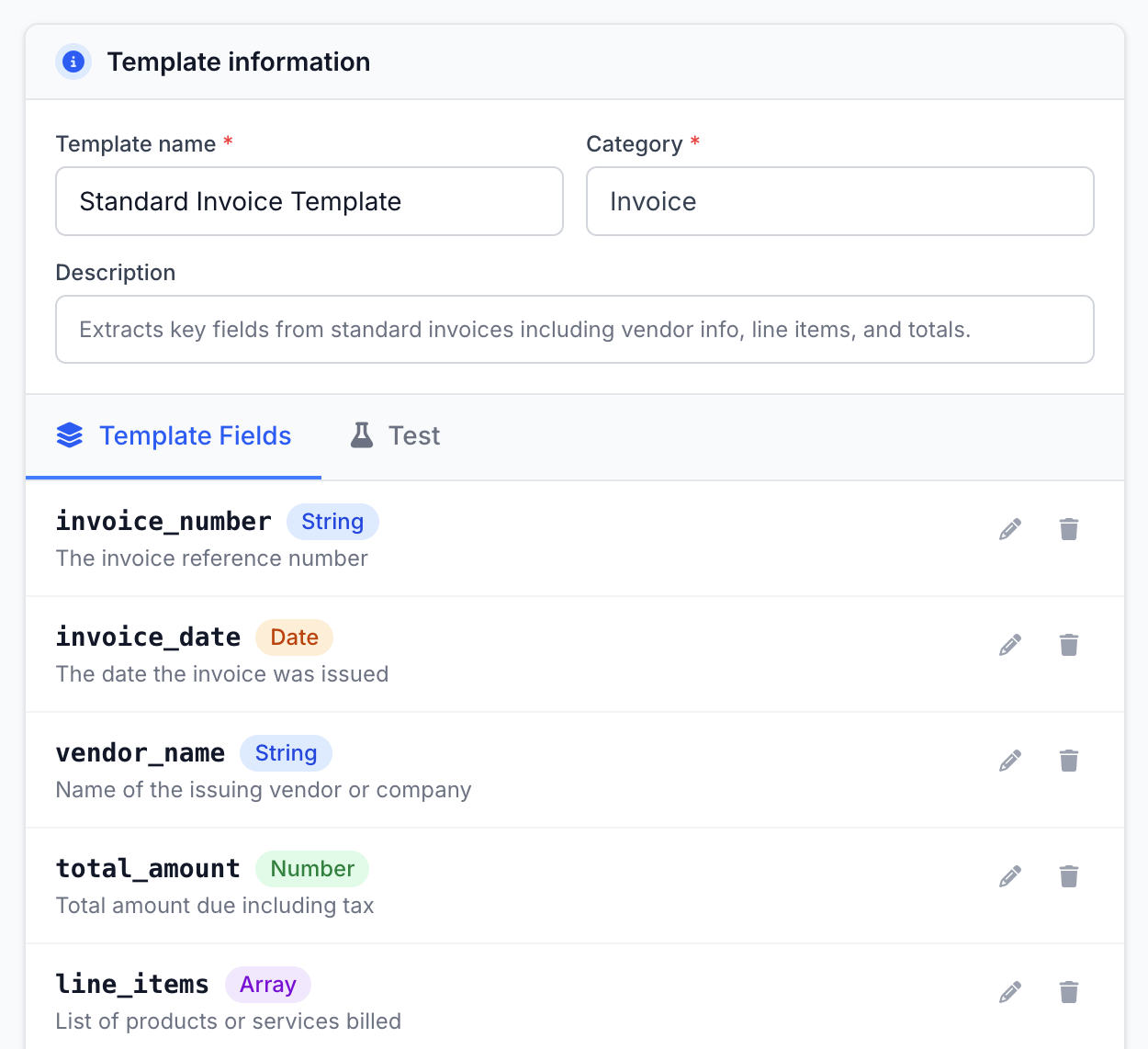
Template Builder
Define extraction fields by name, type, and description. No code required.
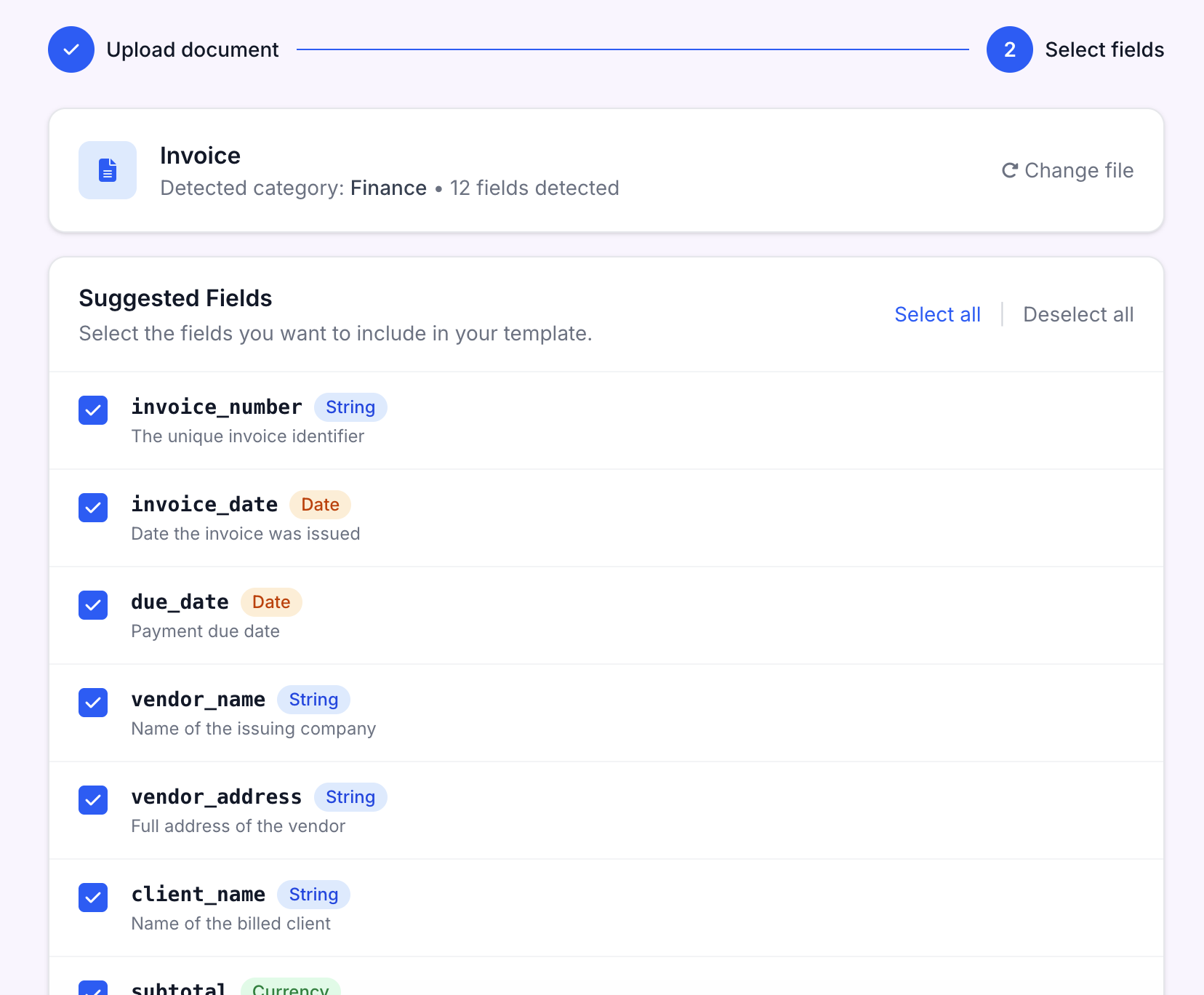
AI Template Wizard
Upload a document and AI auto-detects all extractable fields in seconds.
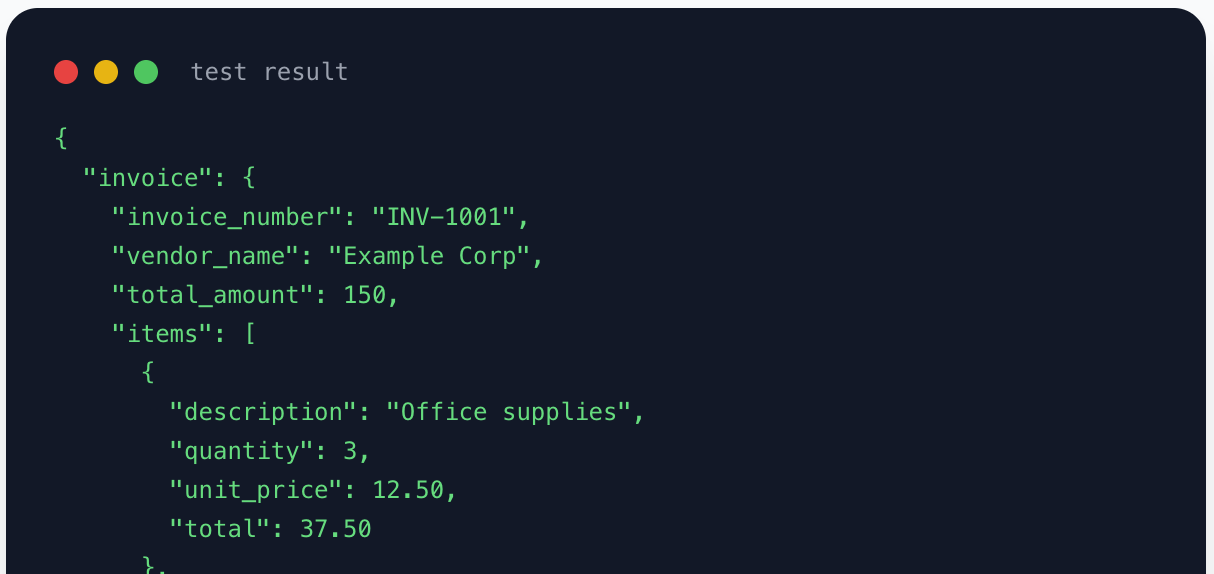
Template Testing
Test templates on real documents right from the editor before going live.
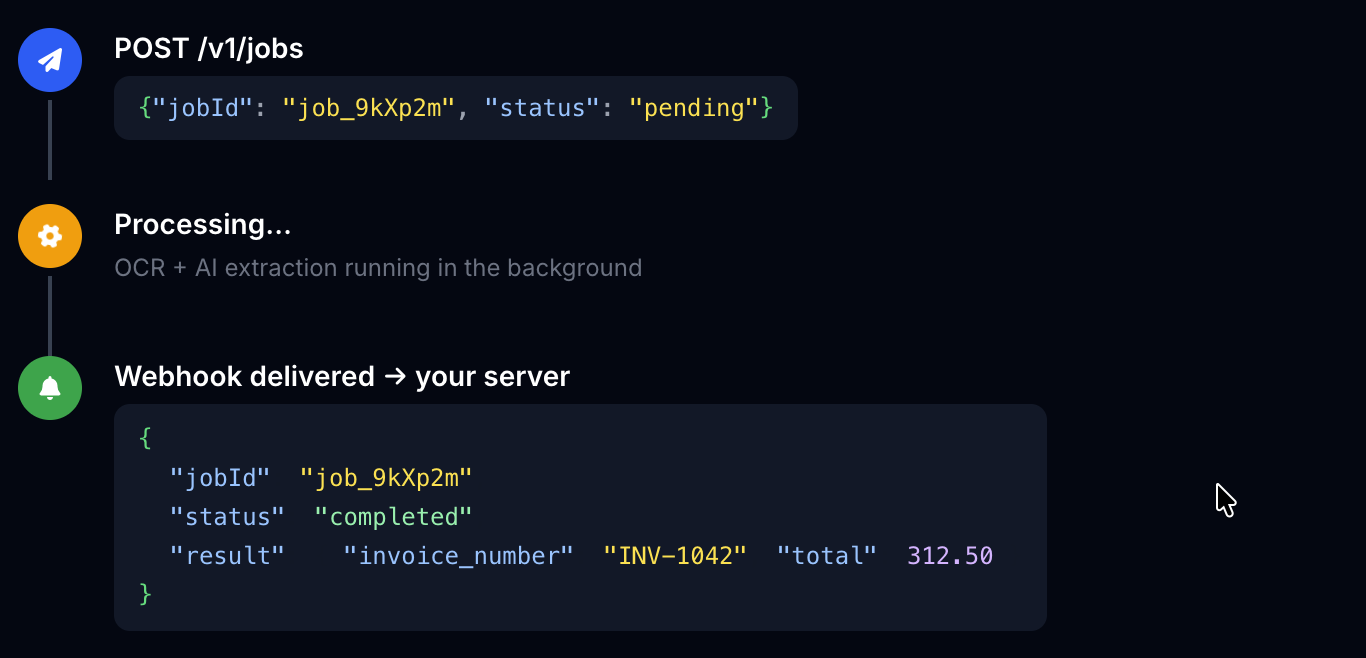
Async Processing and Webhooks
Submit documents in the background and receive a webhook when done.
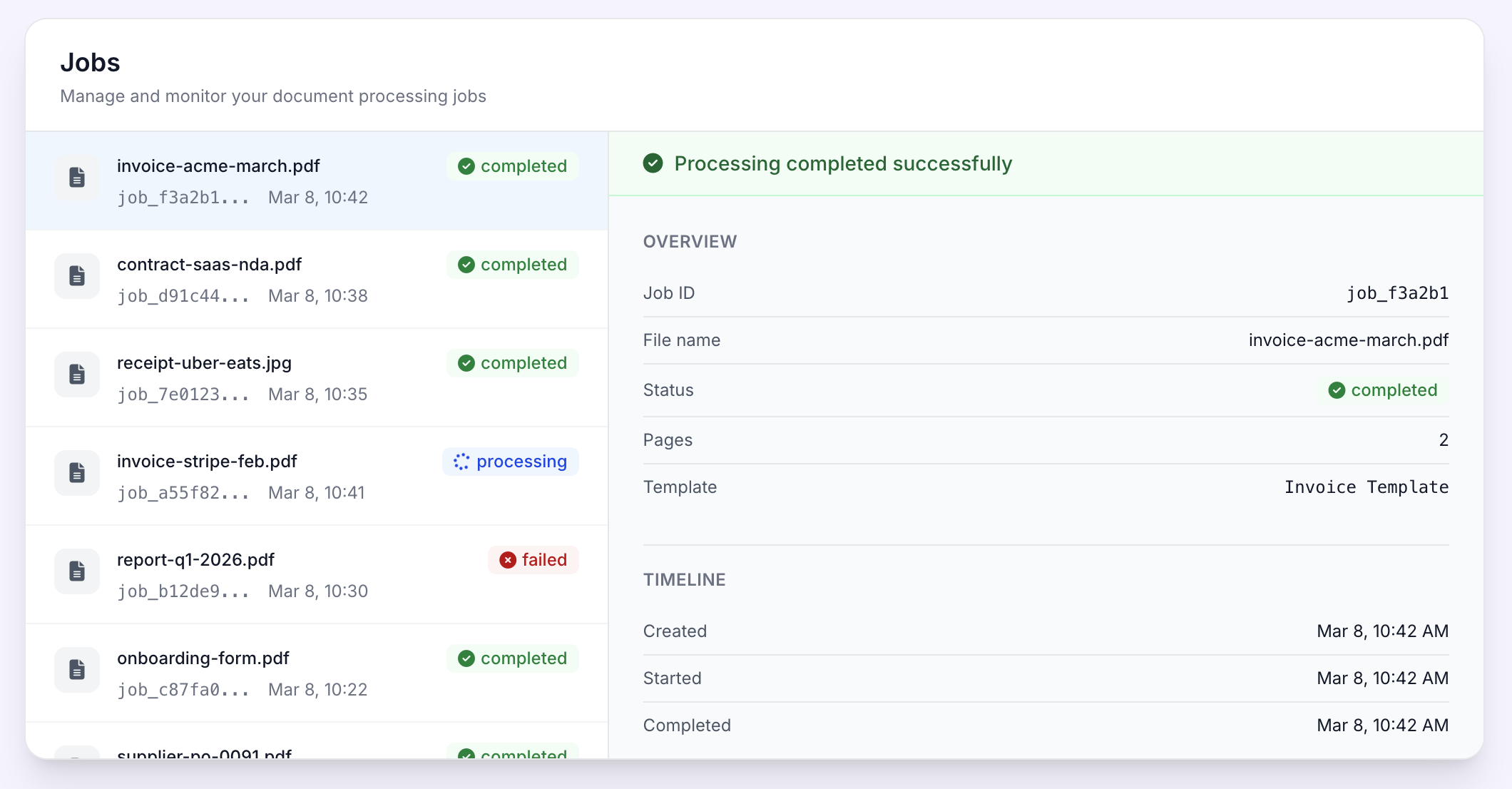
Job History and Monitoring
Track every extraction job: status, result, page count, and timestamps.
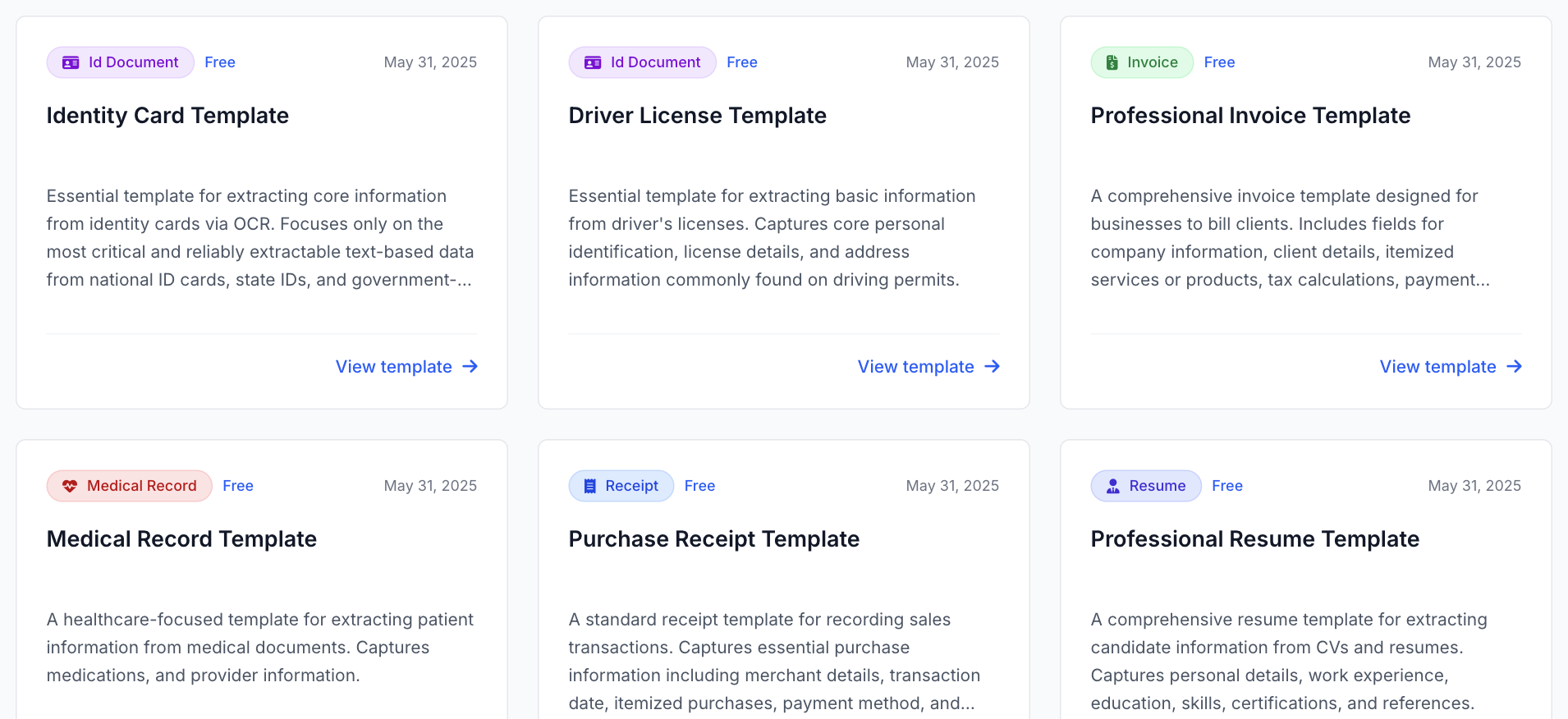
Template Marketplace
Browse and import ready-made templates for any document type.
From document to working template in 3 steps
The fastest path: let AI do the heavy lifting, then refine and test.
AI detects your fields
Upload any sample document. The AI Wizard identifies every extractable field instantly — no manual work.
AI Template WizardRefine in the editor
Rename fields, change types, add descriptions. The Template Builder gives you full control over what gets extracted.
Template BuilderTest on real documents
Run a live extraction right from the editor. See the JSON result immediately, adjust, and re-run until it's perfect.
Template TestingAlso included
Core capabilities available on every plan by default.
Advanced OCR Engine
99%+ accuracy, 50+ languages
ZIP / Multi-file Processing
Paid plans, up to 10 files
Multi-page PDF Support
Automatic page detection
Multi-language OCR
50+ languages, auto-detect
REST API
JSON responses, API key auth
Node.js SDK
npm install parselyze
HMAC Webhook Signatures
Verify every delivery
API Key Management
Per-project keys, revokable
Ready to extract data from your documents?
50 pages/month free · No credit card required